Notepad++Good Luck To You!
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。实验工具即环境: 笔记本:Y9000X2020 系统:win10 Python版本:python3.8.6 pycharm版本:pycharm2021...
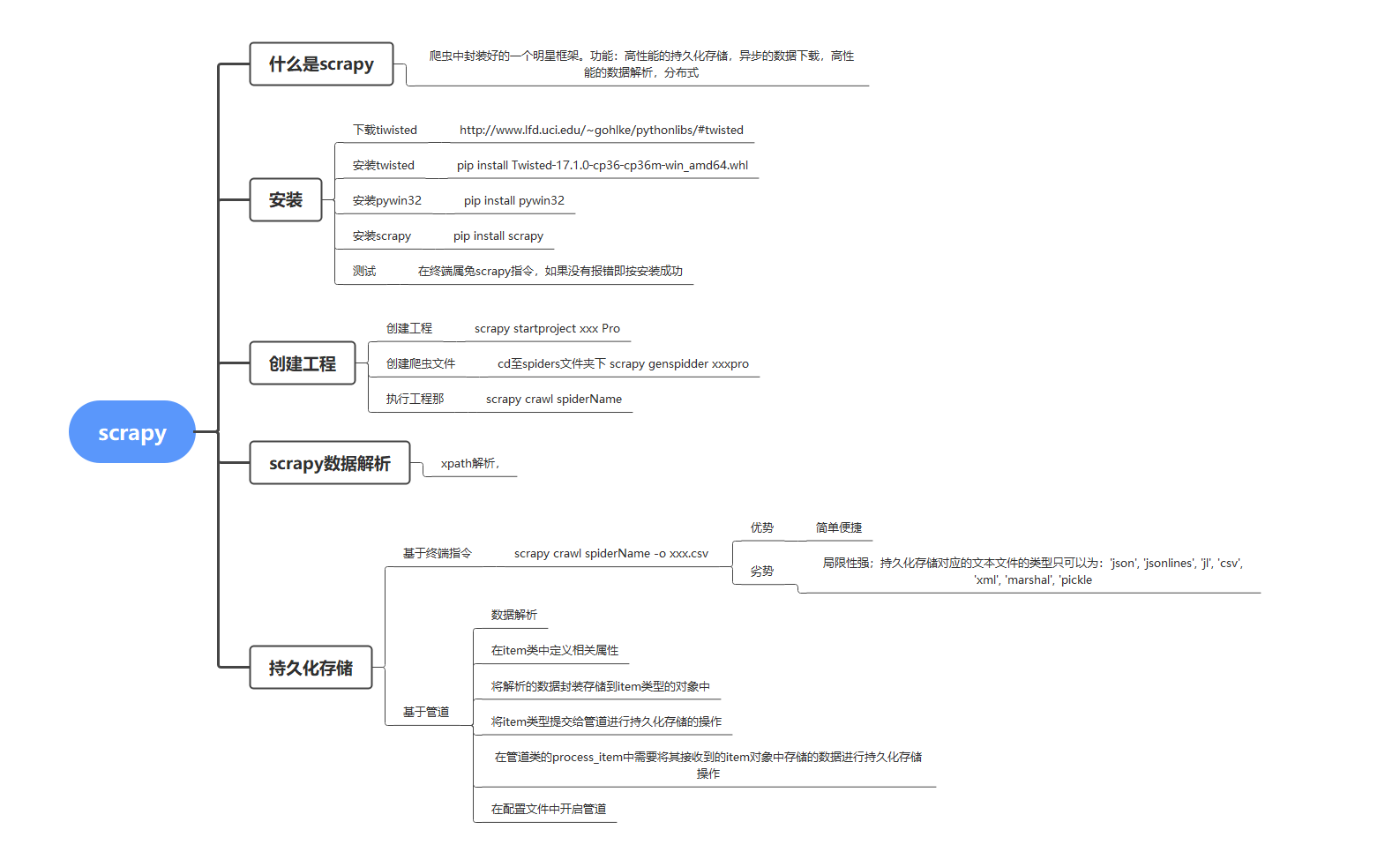
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。
实验工具即环境:
笔记本:Y9000X 2020
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
一、安装
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载好后打开终端进行安装scrapy的必要模块
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
安装完成后在终端输入scrapy如果没有报错即安装成功。
二、创建scrapy的工程
在pycharm中创建好的项目中的中终端输入
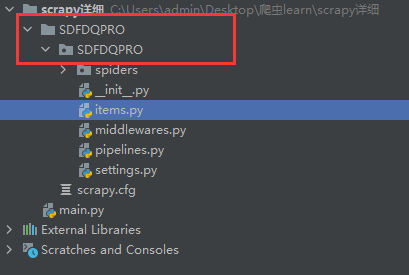
scrapy startproject SDFDQPRO

检查下项目目录即可发现多出了如下的工程目录
三、创建一个爬虫目录
在终端找到之前所创建的工程目录,在此目录下输入scrapy genspider sdfdq_cj http://www.csrc.gov.cn/pub/shandong/
后方网站为中国证券监督管理委员会山东监管局。

运行后可发现工程目录中多出一个名为sdfdq_cj.py的爬虫文件。

进入到爬虫文件中可以看到如下代码
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
pass
接下来对网站解析选取需要获取的内容
四、数据解析
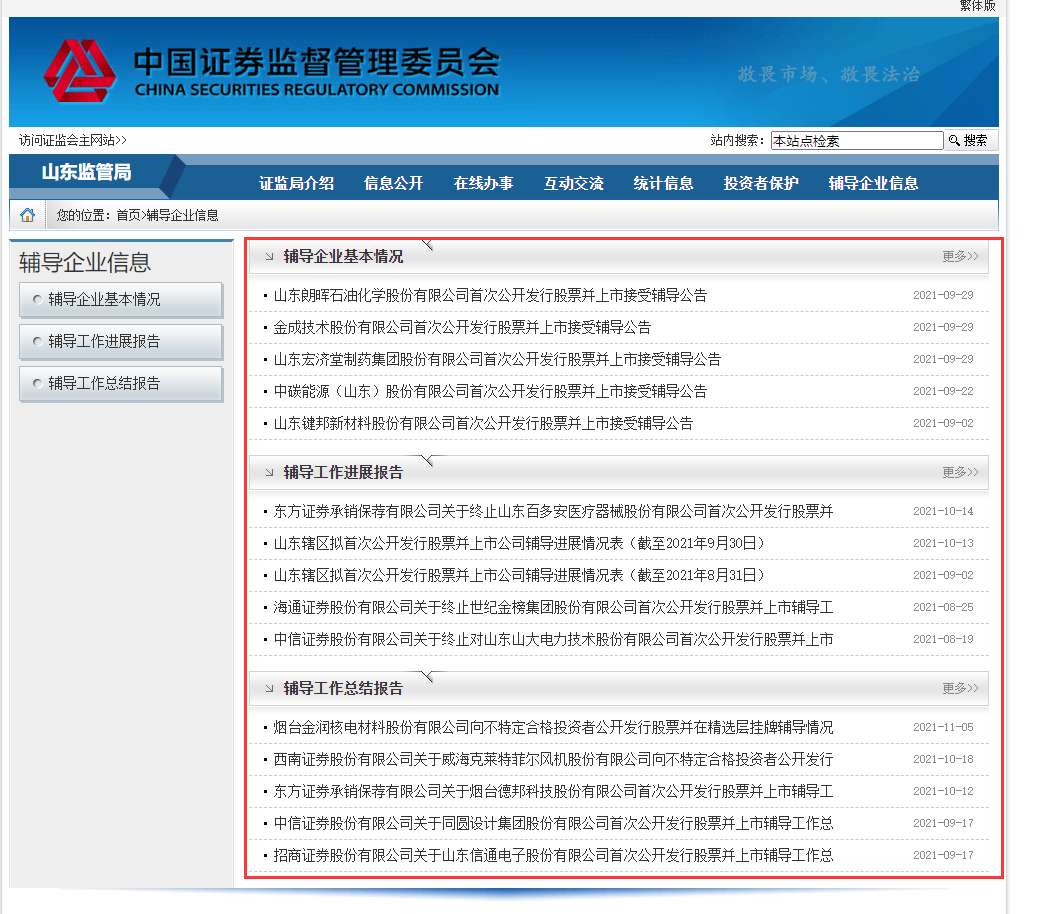
通过对网站的查看可以看出我们需要的是辅导期中的企业基本情况、工作进展报告、工作总结总的标题,日期以及链接。
scrapy对网站的解析沿用了xpath的解析方式。
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
print('title',title)
print('url',url)
print('date',date)
对网站的内容解析后运行scrapy 终端输入 scrapy crawl sdfdq_cj 注意:此语句的运行目录

可以看到我们想获取的内容:
内容获取到我们必须要将其持久化存储才有意义:
五、scrapy的持久化存储
1)基于指令的持久化存储:
要求:只可以将parse的方法返回值存储到本地的文本文件中
def parse(self, response):
# 创建一个列表接收获取的数据
all_data = []
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
# 基于终端指令的持久化存储操作
dic = {
'title':title,
'url':url,
'date':date
}
all_data.append(dic)
return all_data
接下来在终端中输入 scrapy crawl sdfdq_cj -o ./sdfdq.csv
将获取的文本内容存储到对应路径下的sdfdq.csv文本文件中

-----第二更-----
补充下知识点 在进行scrapy时需要对配置文件settings的权限进行一定的修改:
BOT_NAME = 'SDFDQPRO'
# 日志输出
LOG_LEVEL = 'ERROR'
SPIDER_MODULES = ['SDFDQPRO.spiders']
NEWSPIDER_MODULE = 'SDFDQPRO.spiders'
# UA伪装
USER_AGENT ='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'SDFDQPRO (+http://www.yourdomain.com)'
# Obey robots.txt rules
# ROBOTSTXT_OBEY协议 此条分享严格遵守此协议/可根据个人的需求将True 改为FALSE
ROBOTSTXT_OBEY = True
2)基于管道的持久化存储
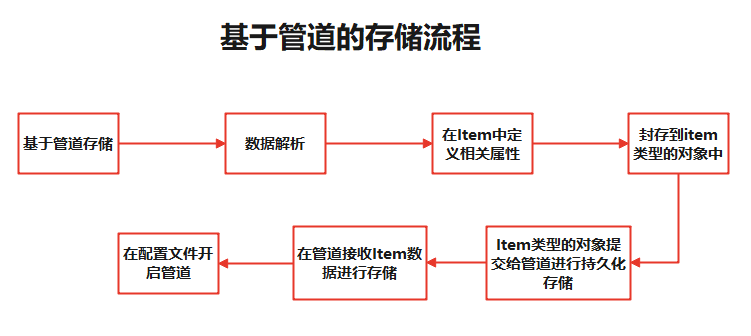
数据解析的步骤昨天已经分享好了接下来按照上方流程图来进行基于管道的存储方式
一、在Item中定义相关属性:
在项目目录下打来items文件进行配置
import scrapy
class SdfdqproItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
url = scrapy.Field()
date = scrapy.Field()
二、将数据封存到item类型对象中
将数据封存到item类型对象中我们需要在爬虫文件中引用到配置好的items文件中的类的方法SdfdqprItem
#应用item中的方法
from SDFDQPRO.items import SdfdqproItem
#将解析后数据封装到Item中
item['title'] = title
item['url'] = url
item['date'] = date
三、Item类型的对象提交给管道进行持久化存储:
yield item
四、在管道接收Item数据进行存储
在pipelines.py文件中进行管道接收Item的操作,
因为我们获取数据的方式基于管道所以没传输一次管道都会运行一次,故需要自己写两个方法(open_spider,close_spider)在里面
class SdfdqproPipeline:
fp = None
# 开始只会被调用一次
def open_spider(self,spider):
print('spider_start')
self.fp=open('fdq.txt','w',encoding='utf-8')
# 用来处理Item类型对象
# 此方法可接收爬虫文件提交过来的Item对象
# 没接收一次item就会被调用一次
def process_item(self, item, spider):
title = item['title']
url = item['url']
date = item['date']
self.fp.write(title+','+url+','+date+'\n')
return item
# 结束只会被调用一次
def close_spider(self,spider):
self.fp.close()
print('spider_end')
五、开启管道
在配置文件中找到下方的代码取消注释即可开启管道
ITEM_PIPELINES = { 'SDFDQPRO.pipelines.SdfdqproPipeline': 300,# 数值表示优先级 越小优先级越大}
截止至2021.11.10爬虫文件的全部代码在下面啦!!
import scrapy
from SDFDQPRO.items import SdfdqproItem
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
# 创建一个列表接收获取的数据
all_data = []
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
# 基于终端指令的持久化存储操作
dic = {
'title':title,
'url':url,
'date':date
}
all_data.append(dic)
# 封装管道
item = SdfdqproItem()
item['title'] = title
item['url'] = url
item['date'] = date
# 将item提交给管道
yield item
--------第三更--------
基于管道将数据存储到数据库
python链接数据库的方法:
安装:pymsql pip install pymysql
一、新建一个数据库来存储即将接收的数据
注意:在表中需要和我们获取的数据的字段保持一致
CREATE TABLE `fdq` ( `title` varchar(255) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL, `url` varchar(255) COLLATE utf8_bin DEFAULT NULL, `date` datetime DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin
在piplines.py中设置数据库的连接和存储操作
import pymysql
class SdfdqproPipeline(object):
conn = None
cursor = None
def open_spider(self,spider):
print('write_start')
# 设置数据库接口
self.conn = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='123', db='fdq',charset='utf8')
def process_item(self,item,spider):
# 设置数据游标
self.cursor = self.conn.cursor()
try:
self.cursor.execute('insert into fdq values("%s","%s","%s")'%(item["title"],item["url"],item['date']))
self.conn.commit()
# 如果数据存储异常就回滚
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self,spider):
# 关闭数据库链接
self.conn.close()
self.cursor.close()
print('write_over')
然后开始运行 scrapy crawl sdfdq_cj j 完成后就可以在我们的数据库中看到获取后的数据了:
全文详见:http://xpxw.com/?id=163